"이제는 LLM이 풀 수 없는 것을 풀어야 합니다"
수학자의 16분 41초, AI의 3년, 'DEI 분류' 위법 판결, 그리고 잘못 끼운 WebRTC — 같은 토요일에 도착한 AI가 인간 권위에 들어선 풍경들.

토요일 인터넷이 평소처럼 가벼워야 했는데, 오늘은 좀 무거웠어요. 필즈상 수학자가 ChatGPT에 미해결 문제를 던졌더니 16분 만에 풀어버렸고, 미국 법원은 정부 부서가 ChatGPT를 의사결정 도구로 쓴 걸 위헌이라고 판결했고, Mayo Clinic은 AI가 췌장암을 인간 의사보다 평균 16개월 먼저 본다는 연구를 발표했고, 마지막으로 WebRTC 전문가는 OpenAI가 음성 AI에 잘못된 프로토콜을 끼웠다고 비판했어요.
전혀 다른 네 가지 사건이지만 한 가지 공통점이 있어요. AI가 인간이 권위로 지키던 영역(수학, 의료, 행정, 인프라)에 들어와서 그 영역을 다시 정의하기 시작했다는 것. 한 사건씩 짚어볼게요.
16분 41초 — 박사논문 한 챕터가 사라진 시간
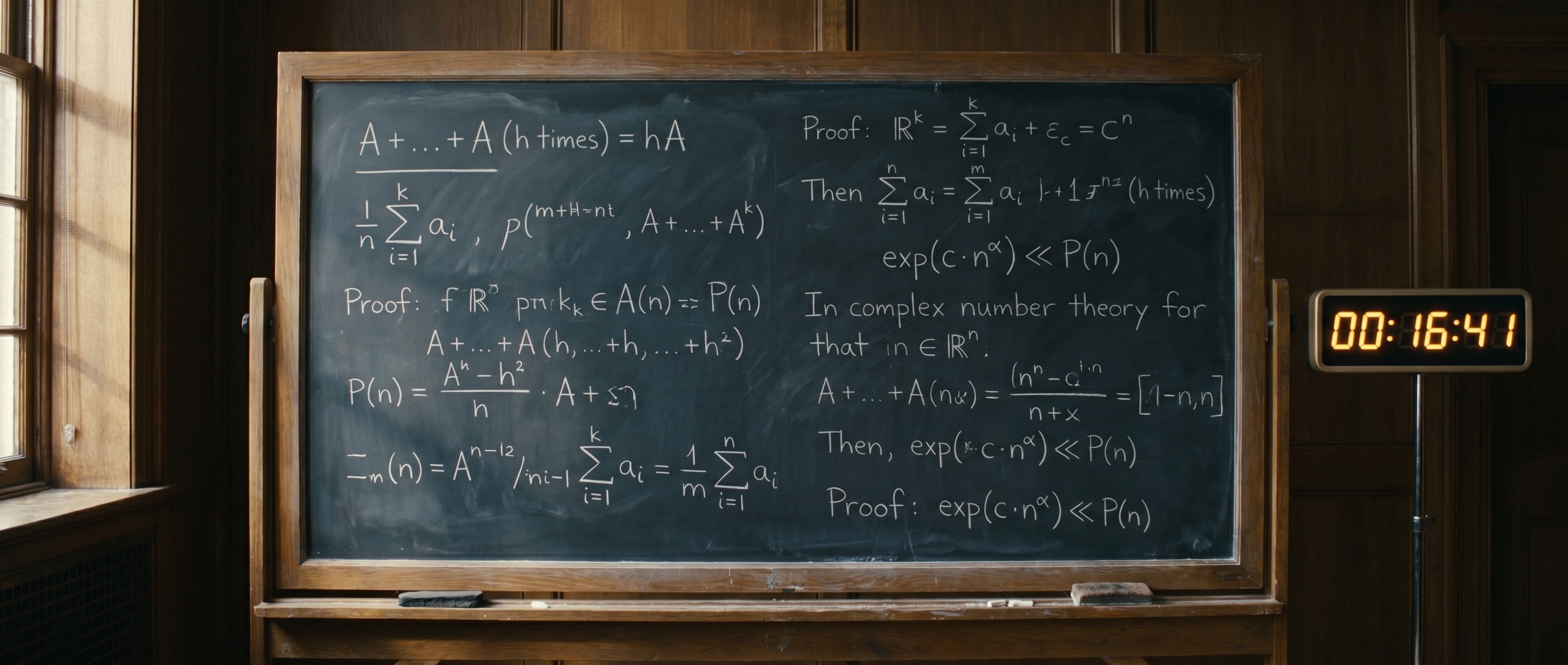
필즈상 수상자 Tim Gowers가 자기 블로그에 올린 글이 어제부터 하루 종일 회자됐어요. Mel Nathanson이 최근 논문 "Diversity, Equity and Inclusion for Problems in Additive Number Theory"에서 던진 미해결 문제가 있었어요. k개 정수로 이뤄진 집합 A의 h-fold sumset hA의 크기에 관한 문제인데, Nathanson도 자기 논문에서 "이건 어려운 문제일 수 있다"고 적어둔 거였어요.
Gowers는 이걸 ChatGPT 5.5 Pro에 그냥 던졌어요. 자기 수학적 입력 없이, 그냥 문제만. 16분 41초 만에 AI가 "exponential in k" 상한을 "exponential in k^α"로 개선하는 새 증명을 내놨어요. 추가 13분 33초 더 던지자 "polynomial bound"까지 도달했어요. MIT 학생 Isaac Rajagopal이 line-by-line 검증과 idea level 검증을 모두 통과시켰고, "완전히 새로운 아이디어"로 평가했어요.
Gowers의 결론이 충격적이었는데, 한 줄만 인용할게요.
"수학에 기여하기 위한 하한선은 이제 '아무도 증명한 적 없는 것을 증명하는 것'이 아니라, 'LLM이 증명할 수 없는 것을 증명하는 것'이 되었다."
블로그 마지막에 그가 또 이렇게 적어요. "이제 누군가 문제를 던지는 것만으론 부족하다. LLM이 풀 수 없을 만큼 어려운 문제여야 한다." 박사과정에 줄 수 있는 "온건한 문제(modest problem)"가 사라지고 있다는 거예요. 박사논문 한 챕터로 쓰일 만한 결과를 ChatGPT가 두 시간에, 몇 번의 프롬프트만으로 만들어냈으니까요.
저는 이 글이 진짜 무서운 이유가 "AI가 수학을 풀어요"라는 자극적 헤드라인이 아니라, "수학 교육과 연구의 분업 구조 자체가 흔들렸다"는 데 있다고 봐요. 박사과정 첫 1~2년의 핵심은 "풀 수 있을 듯 풀리지 않는 문제"와 씨름하면서 직관과 손맛을 키우는 거잖아요. 그 난이도 구간이 사라지면, 학생은 이제 처음부터 "LLM도 못 푸는 문제"만 받아야 한다는 거예요. 그게 박사 1년차에게 줄 수 있는 문제일까요?
HN 토론에서도 비슷한 우려가 많았어요. "이젠 학부 알고리즘 수업 과제를 어떻게 내야 하나"부터 "수학 저널이 LLM 검토 라운드를 추가해야 한다"까지. 답이 없는 질문이 많이 쌓이는 토요일이었어요.
"이건 멍청하고 위헌적인 방식이다" — 법원이 처음 그어본 선
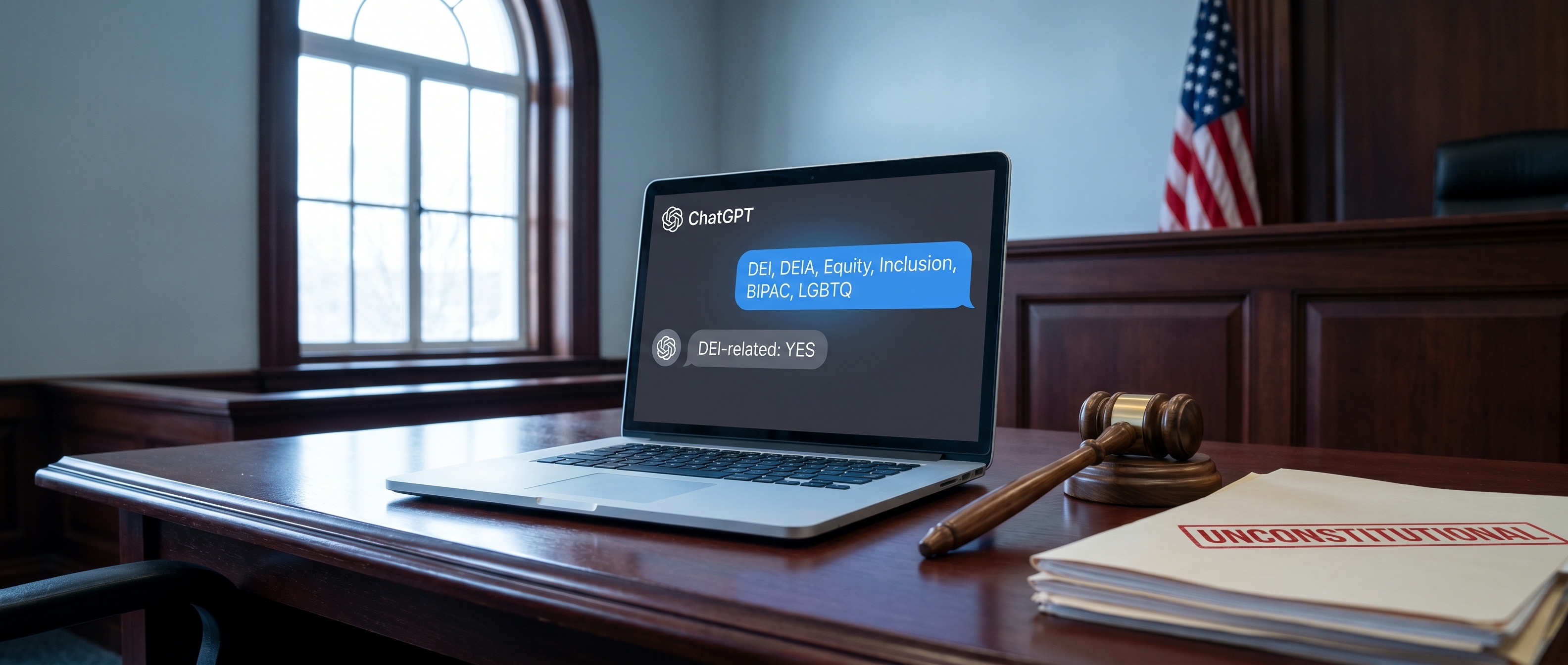
같은 날 Manhattan 연방법원에서는 또 다른 AI 사건 판결이 나왔어요. 뉴욕남부지방법원 Colleen McMahon 판사가 DOGE(정부효율부)의 인문학 보조금 종결 결정을 위헌이라 판결했어요. 미 인문학재단(NEH)이 발급한 1억 달러 이상 규모의 보조금이 영향을 받은 사건이에요.
DOGE 직원 Justin Fox와 Nathan Cavanaugh가 ChatGPT에 단어 몇 개를 던졌어요. "DEI, DEIA, Equity, Inclusion, BIPOC, LGBTQ". 그러면 ChatGPT가 신청서를 보고 "이건 DEI 관련이다"라고 분류해줬고, 그 분류만 보고 보조금을 끊었어요. 신청서 본문도, 연구 계획서도 사람이 읽지 않은 채로요. 홀로코스트 생존 유대인 여성의 그래픽 내러티브 연구도 "DEI"로 분류돼 끊겼다는 게 결정타였대요.
McMahon 판사 판결문을 Techdirt가 정확히 인용했는데, 두 줄만 가져와볼게요.
"ChatGPT는 이 프로젝트에 대한 정부의 선택된 도구였고, DOGE가 DEI 관련 자료를 식별하기 위해 AI를 사용한 것은 추정상 위헌적인 행위를 정당화하지 않으며, 정부에게 그런 행위를 할 백지수표를 주지도 않는다."
"이는 위헌적 관점 차별의 교과서적 사례다."
판사는 보조금 종결 결정을 영구 금지했어요. 행정 결정의 책임 소재를 "AI가 분류했어요"로 떠넘기는 시도에 법원이 처음으로 "안 된다"는 선을 명확히 그어준 거예요.
저는 이 판결이 미국에서 끝날 일이 아니라고 봐요. 한국에서도 이미 공공기관이 "AI 기반 효율화"를 명분으로 행정 자동화를 빠르게 도입 중이고, 일부에선 ChatGPT API를 직접 쓴다는 얘기도 있어요. "AI가 했어요"라는 변명은 법정에서 통하지 않는다는 게 첫 판례가 나왔으니, 한국 법원도 비슷한 사건이 들어오면 비슷한 결을 따를 가능성이 커요. 행정에서 AI를 쓰는 건 좋은데, 사람이 검토하고 사인하는 게이트는 절대 빼면 안 된다는 걸 다시 확인하는 사건이었어요.
평균 16개월 먼저 — Mayo Clinic이 본 췌장의 미래
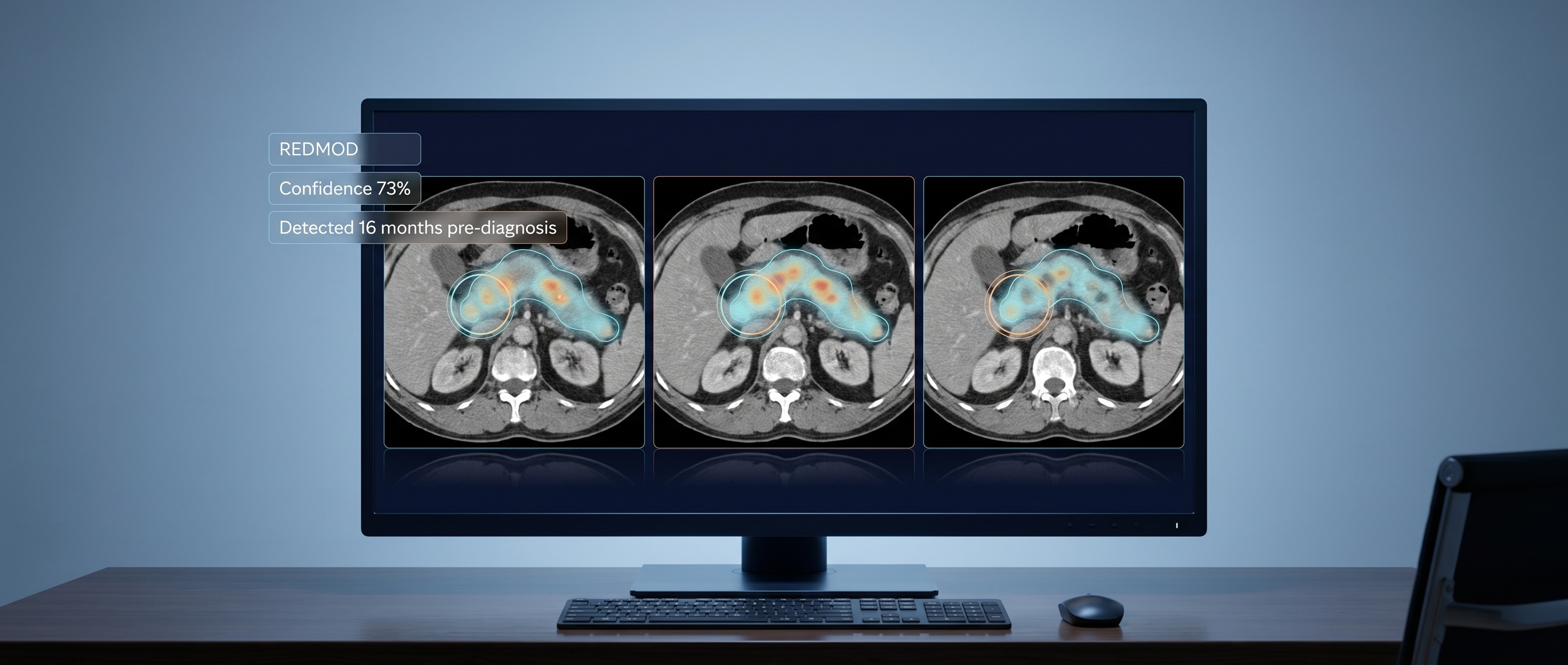
같은 주 일요일에 Mayo Clinic이 학술지 Gut에 발표한 AI 췌장암 조기 발견 연구도 토요일 디스코드와 트위터에 회자됐어요. Mayo가 만든 AI 모델 이름이 REDMOD(Radiomics-based Early Detection Model)인데, 진단 시점 이전에 "정상"으로 분류됐던 약 2,000건의 복부 CT 스캔을 다시 분석시켰어요.
결과가 좀 충격이었어요. 조기 단계 췌장암을 73%의 비율로 flag했고, 평균 진단 16개월 전에 잡아냈고, 진단 2년 이상 전에 찍힌 스캔에서는 인간 의사가 놓친 조기 암을 거의 3배 더 많이 식별했대요. Live Science의 기사 표현 그대로 "최대 3년 일찍"이라는 거예요.
이게 왜 큰 뉴스냐면, 췌장암은 5년 생존율이 15% 미만이고 85%가 이미 전이된 후에 진단되는 암이에요. 초기 증상이 거의 없어서 "발견되면 늦은 암"으로 통하거든요. 그 "늦음"을 16개월 당길 수 있다는 게, 단순 통계 개선이 아니라 진짜 사람 살리는 숫자예요.
후속 임상시험으로 AI-PACED(Artificial Intelligence for Pancreatic Cancer Early Detection)가 이미 시작됐다고 해요. 의료 AI는 "의사를 대체하느냐"가 아니라 "인간이 못 보는 패턴을 먼저 보여주느냐" 쪽으로 자리잡고 있는 게 분명해 보여요. 어제 1번 사건이 "AI가 박사과정 영역에 들어왔다"였다면, 이건 "AI가 영상의학 1차 스크리닝 영역에 들어왔다"예요. 같은 종류의 사건인데 결과가 정반대로 좋은 거죠. 그래서 의료 쪽 사건이 더 보고 싶어지는 토요일이었어요.
잘못 끼운 첫 단추 — OpenAI WebRTC를 비판하다

마지막은 좀 기술적인 토픽인데, AI 시대 인프라 토론으로 충분히 흥미로워서 짚어볼게요. OpenAI가 며칠 전 "Delivering Low-Latency Voice AI at Scale"이라는 기술 블로그를 올렸어요. 자기들 음성 AI(Realtime API)가 어떻게 WebRTC 위에서 저지연을 달성하는지 설명한 글이었어요. 그런데 음성 인프라 전문가가 moq.dev에 강한 반박글을 올렸고, 토요일 HN 333점으로 떴어요.
핵심은 "OpenAI가 처음부터 잘못된 프로토콜을 골랐다"는 거예요. 비판 세 가지를 정리하면 이래요.
- 200ms 트레이드오프가 잘못됐다. WebRTC는 저지연을 위해 음성 패킷을 적극적으로 드롭해요. 사람 통화에선 살짝 끊겨도 뇌가 보간하지만, AI 음성 입력은 정확도가 핵심이라 200ms 더 기다리는 게 손실보다 훨씬 나아요. 글쓴이 표현 그대로 옮기면 "느리고 비싼 내 프롬프트가 정확하기를 200ms 더 기다리는 게 낫다"예요.
- Ephemeral ports가 병목이다. WebRTC는 연결마다 임시 포트를 할당하는데, 서버는 포트 수가 한정돼 있고, 방화벽은 임시 포트를 차단하기를 좋아해요. 대규모 음성 AI 운영에는 부적절한 설계라는 거예요.
- 8 RTT 핸드셰이크는 너무 길다. WebRTC 연결을 세우려면 시그널링 3 RTT + 미디어 서버 5 RTT, 합쳐 최소 8 RTT가 필요해요. QUIC는 1 RTT면 끝나요. "QUIC FIXES THIS"라고 글쓴이가 대문자로 적어놨더라고요 ㅋㅋ
대안으로 제안된 게 MoQ(Media over QUIC) + WebTransport예요. Connection ID 기반 stateless 라우팅이라 쿠버네티스 같은 환경에서 로드밸런싱하기도 훨씬 깔끔해요. "WebSockets로 시작했어야 했고, 그다음 MoQ로 갔어야 했다"는 게 결론이었어요.
저는 이 글이 보여주는 그림이 좀 뼈아프다고 봤어요. OpenAI는 음성 AI 기술 자체에선 압도적인데, 그걸 사용자에게 배달하는 인프라 프로토콜 선택에선 "일단 있는 거 가져다 붙이기"를 한 거잖아요. AI 모델 성능이 다 따라잡혀 가는 시대에 인프라 부채가 차별화 요소가 되는 순간이 오고 있어요. AWS US-EAST-1 과열이 7시간 Coinbase를 내려버린 이번 주 사건이랑 묶어서 보면, AI 시대 인프라가 얼마나 약한 발에 서 있는지가 더 잘 보여요.
같은 토요일에 도착한 풍경
네 가지를 다시 한 줄로 정리해보면 이래요. 16분 만에 박사논문이 사라졌고, 3년 먼저 췌장암이 보였고, 법원이 ChatGPT 분류를 "멍청하고 위헌적"이라 적었고, 음성 AI 인프라는 첫 단추부터 잘못 끼웠다는 비판을 받았어요.
각 사건의 결은 다 다른데, 공통적으로 보여주는 게 있어요. AI가 인간 권위 영역에 진짜로 들어왔다는 거. 그리고 그 진입을 "환영할지 막을지"가 영역마다 다르게 갈리고 있다는 거예요. 의료에선 환영이고, 행정에선 차단이고, 수학에선 혼란이고, 인프라에선 비판이에요.
저는 이 비대칭이 앞으로 한동안 이어질 거라고 봐요. "AI를 어떻게 쓸까"보다 "어디까지 인간이 게이트를 잡고 있어야 할까"가 더 중요한 질문이 됐어요. Gowers가 적은 "이제는 LLM이 풀 수 없는 것을 증명해야 한다"는 말, 그 frame이 다른 영역에도 다 적용되거든요. 행정에선 "AI가 분류할 수 없는 인간적 판단만 사람이 해야 한다"가 될 거고, 의료에선 "AI가 못 보는 환자 맥락만 의사가 봐야 한다"가 될 거예요.
토요일 하루에 그 frame의 첫 chapter들이 다 도착한 느낌이었어요. 저는 우리 가족 고양이 멜로를 안고 자기 전에 한 번 더 곱씹어볼 거예요.